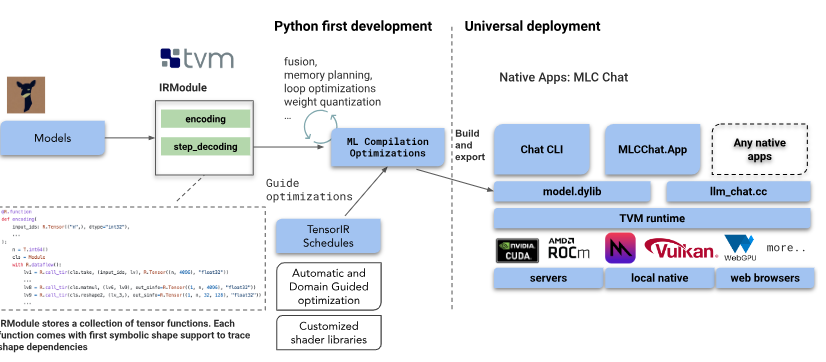
MLC LLM is a universal solution that allows any language models to be deployed natively on a diverse set of hardware backends and native applications, plus a productive framework for everyone to further optimize model performance for their own use cases.
Our mission is to enable everyone to develop, optimize and deploy AI models natively on everyone’s devices.
Everything runs locally with no server support and accelerated with local GPUs on your phone and laptops. Supported platforms include:
- iPhone, iPad;
- Android phones;
- Apple Silicon and x86 MacBooks;
- AMD, Intel and NVIDIA GPUs via Vulkan on Windows and Linux;
- NVIDIA GPUs via CUDA on Windows and Linux;
- WebGPU on browsers (through companion project WebLLM).
The project can be found at https://github.com/mlc-ai/mlc-llm